영상 처리 프로그래밍에 있어서 가장 많이 접하는 타입이 바로 2차원 배열이다. C/C++ 에서는 모든 자료형에 대하여 다차원 배열을 지원하고 있다. 그러나, 기본적인 2차원 배열을 사용하려면 그 크기를 미리 지정해야한다는 단점이 있다. 그러나, 다양한 크기의 영상을 배열에 넣기 위해서는 배열의 크기가 프로그램 동작 시간에 결정되게 마련이고, 그 때문에 new 연산자를 이용한 동적 배열 할당이 필요하다.
가장 일반적인 형태의 2차원 배열 동적 할당 방법은 다음과 같다.
위의 코드를 그림으로 설명하면 다음과 같다.
위의 코드에서 주의해야 할 점은 할당한 메모리 공간을 해제할 때, 그림상 하늘색으로 표현된 공간을 모두 해제해주어야 한다는 점이다. 즉, 가로로 그려진 하늘색 메모리 공간 w개와 세로로 그려진 메모리 공간 1개를 delete [] <변수이름> 형태로 삭제해주어야 한다는 점이다.
이제 이것과 동일한 역할을 하는, 새로운 2차원 배열 동적 할당 방법을 알아보자. 코드는 다음과 같다.
마찬가지로 이 코드에 대한 그림 설명을 보면 이해가 더 쉽게 되리라 믿는다.
이 새로운 방법에서는 new 연산을 2번만 수행한다는 장점이 있다. 그러므로, for 문을 돌면서 메모리를 할당하거나 해제하는 작업이 없다. pixels[1]~pixels[h-1] 까지는 모두 새로운 메모리를 할당하여 그 위치를 가리키는 것이 아니라, pixels[0] 이 할당한 큰 메모리 공간의 중간을 각각 가리키는 방식을 취한다.
이러한 Alloc2 방법은 배열의 크기가 아주 크지 않을 때에는 Alloc1 보다 어느정도의 속도 향상의 성능을 보여준다. 예를 들어, 256x256 크기의 배열을 10번 할당&해제할 때의 속도를 VC++ 6.0의 Profile 기능을 이용하여 그 시간을 체크해보았다. 실험에 사용한 컴퓨터 환경은 Pentium IV 2.8GHz(3.3GHz로 overclocking), 1GByte RAM, Windows XP sp2 이다.
Func Func+Child Hit Time % Time % Count Function --------------------------------------------------------- 20.624 58.9 20.624 58.9 10 Alloc1(void) (dyna2d.obj) 14.391 41.1 14.391 41.1 10 Alloc2(void) (dyna2d.obj) 0.007 0.0 35.023 100.0 1 _main (dyna2d.obj)
그러나, 배열의 크기를 키우면 그다지 속도 차이가 나지 않음을 발견하였다. 1024x1024 배열을 10번 할당하고 해제할 때의 속도를 보자.
Func Func+Child Hit Time % Time % Count Function --------------------------------------------------------- 297.449 54.1 297.449 54.1 10 Alloc1(void) (dyna2d.obj) 252.632 45.9 252.632 45.9 10 Alloc2(void) (dyna2d.obj) 0.007 0.0 550.087 100.0 1 _main (dyna2d.obj)
사실, 2003년도에 이 Alloc2 방법이 Alloc1 방법보다 매우 빠르다고 생각했었는데, 이번 실험에서 이렇게 결과가 나온 것은 상당히 당혹스러웠다. 그러나, 이번 실험의 하나하나를 다 따져보았으나 잘못된 부분은 발견할 수 없었다. 결국, 속도상에서의 merit 는 그다지 없는 것이 아닌가 하는 결론을 내려야만 했다.
첨부파일은 VC++ 6.0 에서 profile 을 보기 위해 만든 프로젝트와 VC .NET에서 GetTickCount 함수를 이용하여 배열을 할당 & 해제하는데 걸리는 시간을 재는 윈도우용 프로그램의 프로젝트 압축파일이다. 참고하시길...
ps. VC .NET 으로 만든 프로그램으로 256x256 배열을 1000번 할당 & 해제할 경우, 은근히 속도 차이를 나타내는 것을 발견하였다. 흠... 작은 배열일 때는 과연 Alloc2 가 유리한 것인가? ㅡㅡ;
Call FillOutsideRect to fill the area of the view that appears outside of the scrolling area. Use FillOutsideRect in your scroll view’s OnEraseBkgnd handler function to prevent excessive background repainting.
예를 들어, 다이얼로그 박스가 떠있고, 내부적으로 연산량이 많은 작업을 하고 있다고 치자. 다이얼로그에서 cancle 버튼을 클릭하면 내부적인 연산을 취소하고 싶다. 그러나, 일반적으로 이 경우, 윈도우즈는 버튼이 클릭되었다는 메시지 처리를 바로 수행하지 못하고, 단지 메시지 큐에만 넣게된다. 바로 single-thread를 사용하기 때문이다.
이러한 문제를 해결하기 위해서는 multi-thread 를 사용하는 것이 가장 적절한 해법이겠으나, 다소 복잡할 수 있다.
여기서는 single thread를 사용하면서, 주기적으로 메시지 큐를 검사하는 방법을 설명한다.
다음 함수를 보자.
void ProcessMessages() { CWinApp* pApp = AfxGetApp(); MSG msg;
// Parse command line for standard shell commands, DDE, file open CCommandLineInfo cmdInfo; ParseCommandLine(cmdInfo);
이는 command line 인자에 대한 처리를 위한 것인데, 다음과 같이 한줄을 추가한다.
// Parse command line for standard shell commands, DDE, file open CCommandLineInfo cmdInfo; ParseCommandLine(cmdInfo); cmdInfo.m_nShellCommand = CCommandLineInfo::FileNothing;
프로그램을 작성할 때 항상 생각하는 것 중의 하나가 "어떻게 하면 프로그램 동작 속도를 빠르게 할 것인가?" 이다. 이를 위해서 다양한 형태로 프로그램을 작성하고, 그 시간을 측정해본다. 요즘의 컴퓨팅 환경에서는 왠만한 루틴은 GetTickCount 같은 함수로는 시간을 측정할 수 없을 만큼 빠르게 동작한다. 그래서 멀티미디어 타이머라는 것을 사용하기도 한다. 그러나, Visual C++ 6.0 의 Profile 기능을 사용하면 간단하게 0.001 msec 단위까지 연산 속도를 측정할 수 있다.
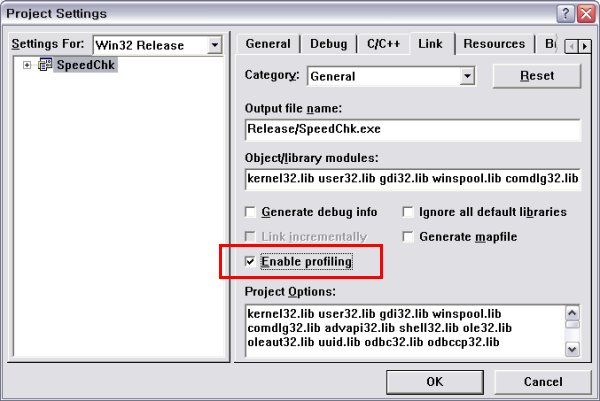
프로파일 기능을 사용하기 위해서는 프로젝트 셋팅에서 프로파일 기능을 활성화(Enable) 시켜주어야 한다. VC++ 6.0 메뉴에서 [Project]->[Settings...]을 선택하면 아래와 같은 대화 상자가 나타난다. 여기서 Link 탭을 선택하고, [Enable profiling] 항목이 선택되도록 한다.
그림에서는 릴리즈 모드에 대하여 [Enable profiling]을 체크하였는데, 이는 릴리즈 모드에서 시간을 재는 것이 합리적(?)이기 때문이다. 아무래도 디버그 모드에서는 함수의 수행 시간에 디버그 정보 처리에 걸리는 시간이 포함되기 때문에 정확한 시간 측정이 불가능하다.
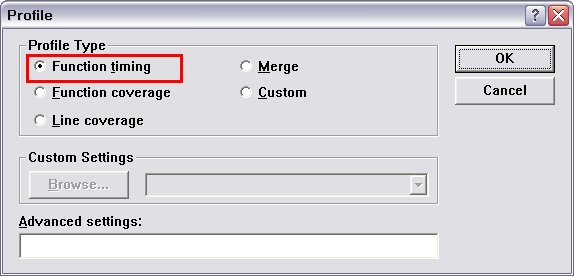
이제 프로그램을 빌드(F7)하고, 에러가 없이 exe 파일이 생성되도록 한다. 에러가 있다면 당연히 에러를 잡아라. 그리고, 메뉴에서 [Build]->[Profile...] 을 선택한다.
그림과 같이 첫번째 항목인 [Function Timing]을 선택하면, 바로 프로그램이 실행되면서 프로그램 수행 시간을 측정하게 된다.
실제 테스트를 해보자. 가급적 프로파일 기능을 사용하려면 콘솔형(도스형) 프로젝트를 만드는 것이 좋다.(아무래도 깔끔하니까...) 다음과 같은 간단한 도스형 프로그램을 만들어보았다.
대충 보면 알 수 있듯이, 1.2의 10승에 대한 연산을 직접 for 문을 사용하여 계산하는 경우와 math 라이브러리에서 제공하는 pow 함수를 사용하여 계산할 때의 시간을 비교하기 위한 프로그램이다. 이 프로그램에 대하여 프로파일을 해보면 출력창(Output window)에 다음과 같은 메시지가 나타난다.
------------------------------------------------------------------------------- Profile: Function timing, sorted by time Date: Wed Apr 06 11:12:23 2005
Program Statistics ------------------ Command line at 2005 Apr 06 11:12: "D:\업로드폴더\SpeedChk\Release\SpeedChk" Total time: 16.673 millisecond Time outside of functions: 11.598 millisecond Call depth: 2 Total functions: 4 Total hits: 20001 Function coverage: 75.0% Overhead Calculated 6 Overhead Average 6
Module Statistics for speedchk.exe ---------------------------------- Time in module: 5.075 millisecond Percent of time in module: 100.0% Functions in module: 4 Hits in module: 20001 Module function coverage: 75.0%
Func Func+Child Hit Time % Time % Count Function --------------------------------------------------------- 3.203 63.1 3.203 63.1 10000 Power2(double,int) (speedchk.obj) 0.988 19.5 5.075 100.0 1 _main (speedchk.obj) 0.884 17.4 0.884 17.4 10000 Power1(double,int) (speedchk.obj) -------------------------------------------------------------------------------
위에 내용을 잘 읽어보기 바라고, 맨 아래 부분 Func Time 부분을 보자. Power2 함수가 전체 3.203 msec 걸린 반면에 Power1 함수는 0.884 msec 밖에 걸리지 않았다. 즉, 1.2의 10승을 계산할 때 직접 for 문을 사용하여 계산하는 것이 더 빠르다는 것을 알 수 있다.
이처럼 프로파일 기능은 특정 루틴의 연산 시간을 편하게 측정할 수 있다. 그러나, 아쉽게도 Visual C++ .NET 버전부터는 이런 Profile 기능이 빠져있다. 돈을 주고 따로 구입해야 한다는 소문이 있는데, 잘 모르겠다. ^^; 아는 분은 답글을 남겨주시길...



 Images.zip
Images.zip